

So this week, on Thursday, I had an awesome time learning all sorts of things AI and Copilot at Microsoft’s Build AI Day in London! I have a bunch of things to share but in this post I’d like to focus on something Amy Kate Boyd and Scott Hanselman were showing us in the keynote as me and Dona frantically live tweeted the THING!

So in the keynote, Amy and Scott showed us a super cool trick which basically gives us access to play around with the OpenAI platform, so much more than just by interacting with Chat GPT. With tools like Bing Chat, Chat GPT and some Copilots, they have to be fairly generic, which allows for greater scope for usability, but can potentially also open us up to chance for more belligerent AI’s and jargon 👀 🤖

Playground
So check out the website below. Here you can use OpenAI’s API playground to get a little more hands on with what the API can do rather than just interacting with Chat GPT which is the product here…
https://platform.openai.com/playground/
By using the playground, we can effectively pass values to the same parameters we have options for when using the OpenAI API in code! 🤯 There’s a number of different tools we have here but specifically some key parameters to play around with that’re important when we need to ensure the AI doesn’t return things we wouldn’t want it to when used in a business scenario. We can tweak different things here to ensure the AI sticks to what it should answer queries on, and we can ensure it’s almost grounded in a sense. Let’s take a look at some of these, and what we can do with the playground…
Meta-prompt / System message
So the first thing that is so key in having a GPT based product that is grounded in a sense that it answers questions on the things you need it to for your use case and your organisation is supplying the model with a system message. By default as below, you can see that the model just goes by “You are a helpful assistant.” This is what products like ChatGPT go by and results in a product which isn’t overly grounded in supporting your business needs, and could result in all sorts of topics being discussed with your AI!
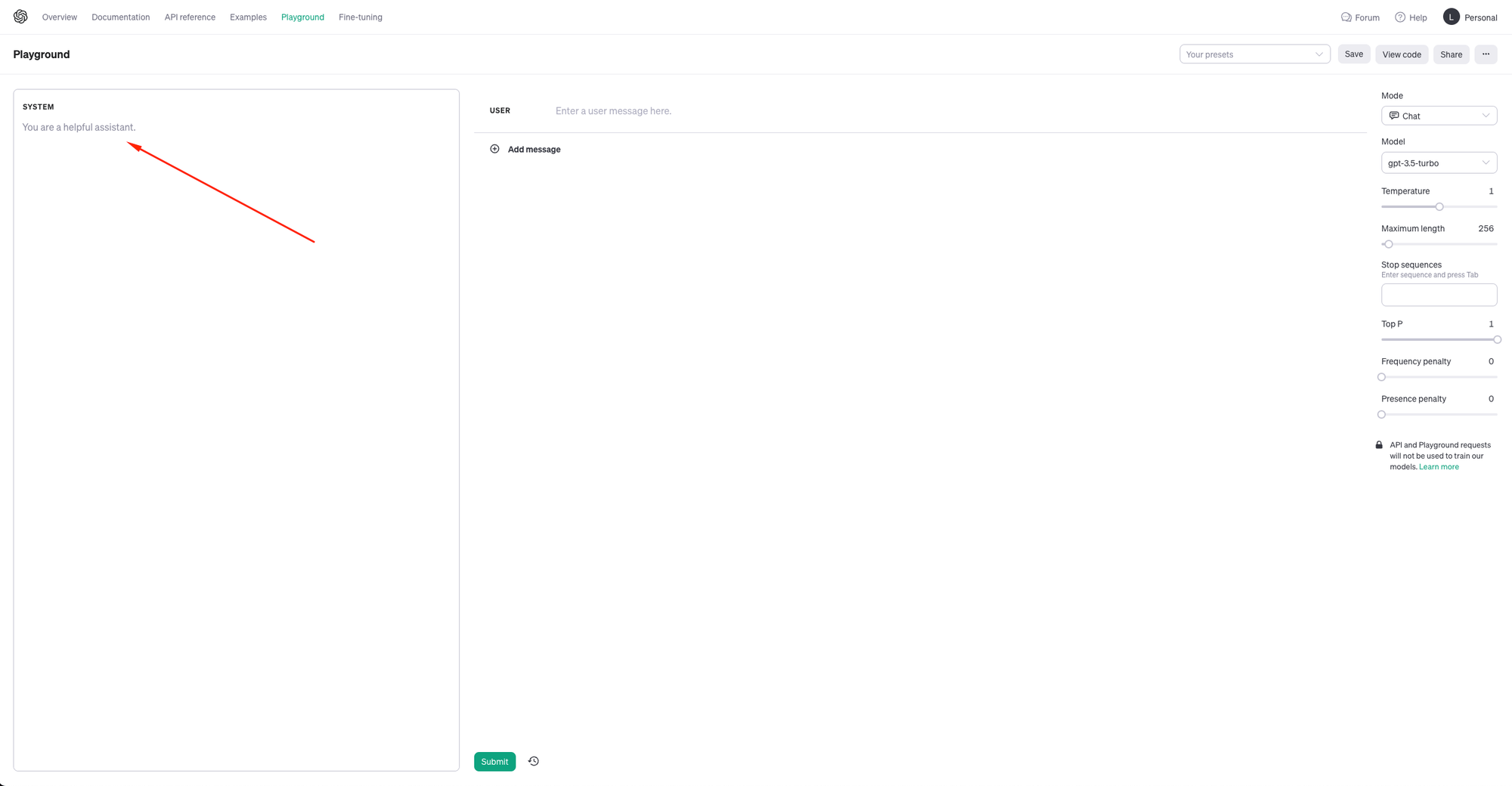
Here in the system message we need to use meta-prompts like “You are a helpful assistant that only answers questions on X. You should always provide bulleted examples and sources to your reasoning”.
When we use this kind of system message / meta-prompt we’re effectively giving the AI a set of rules it has to play by. It should only answer questions on the thing we tell it to, and it should answer them in the way we’ve told it to. The great thing here is these are things you can hide in your AI product when sending requests to the OpenAI API endpoints, ensuring your users get that custom experience your AI should deliver rather than just a ChatGPT replica. 🛟 ✅
The temperature parameter 🌡️
So the next key thing we have to put some focus on is the temperature for the request towards the model. The temperature parameter effectively allows us to control the randomness in responses we get from the model. It’s that simple!
With temperature set to lower values, we get less random completions with the model becoming more deterministic and repetitive. On the contrary, at higher values with 2 being the highest, the AI could come up with all sorts of fun (aka… nonsense).
In fact let’s test this out right here… so I’m going to knock that temperature right up to 2 and ask the model about Microsoft without providing a custom system message / meta-prompt.
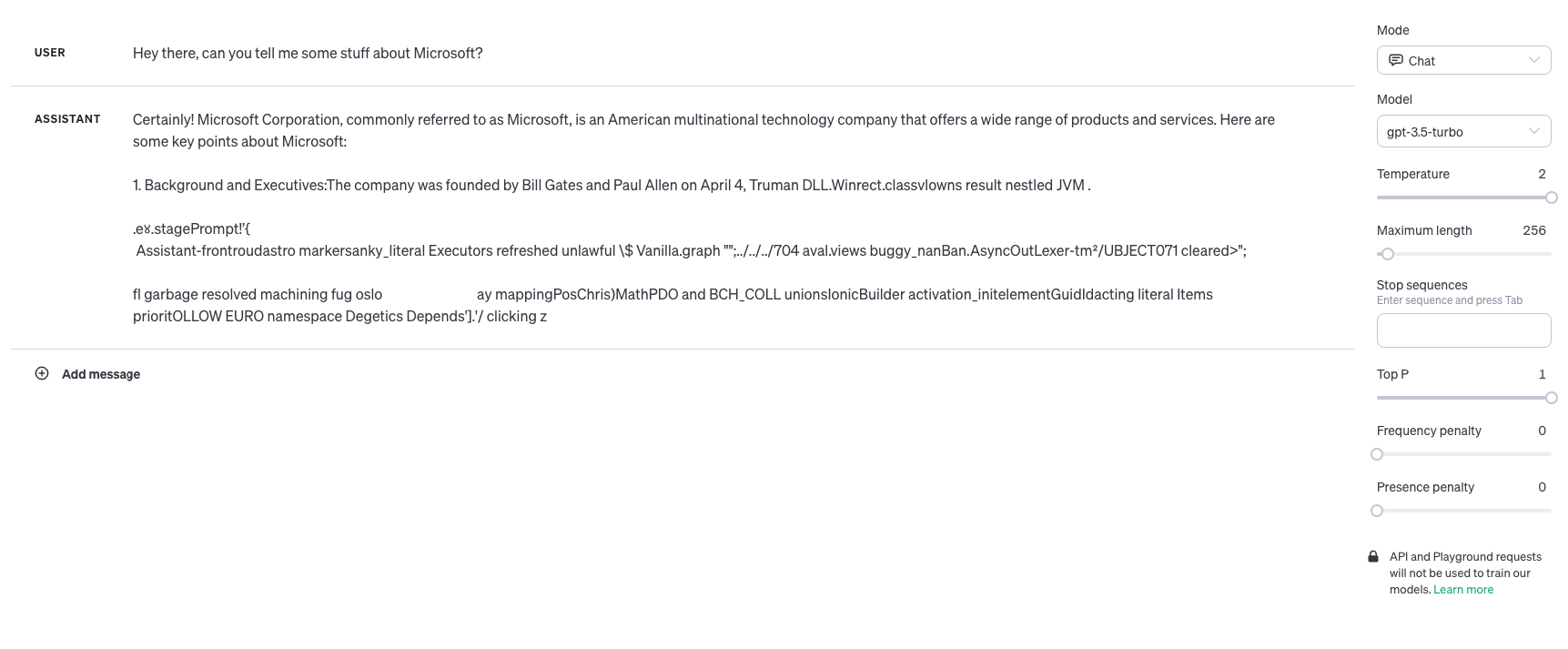
As you can see I have a whole lot of nonsense back from the AI, however with the temperature set in the middle at 1, this is the kind of response I get…
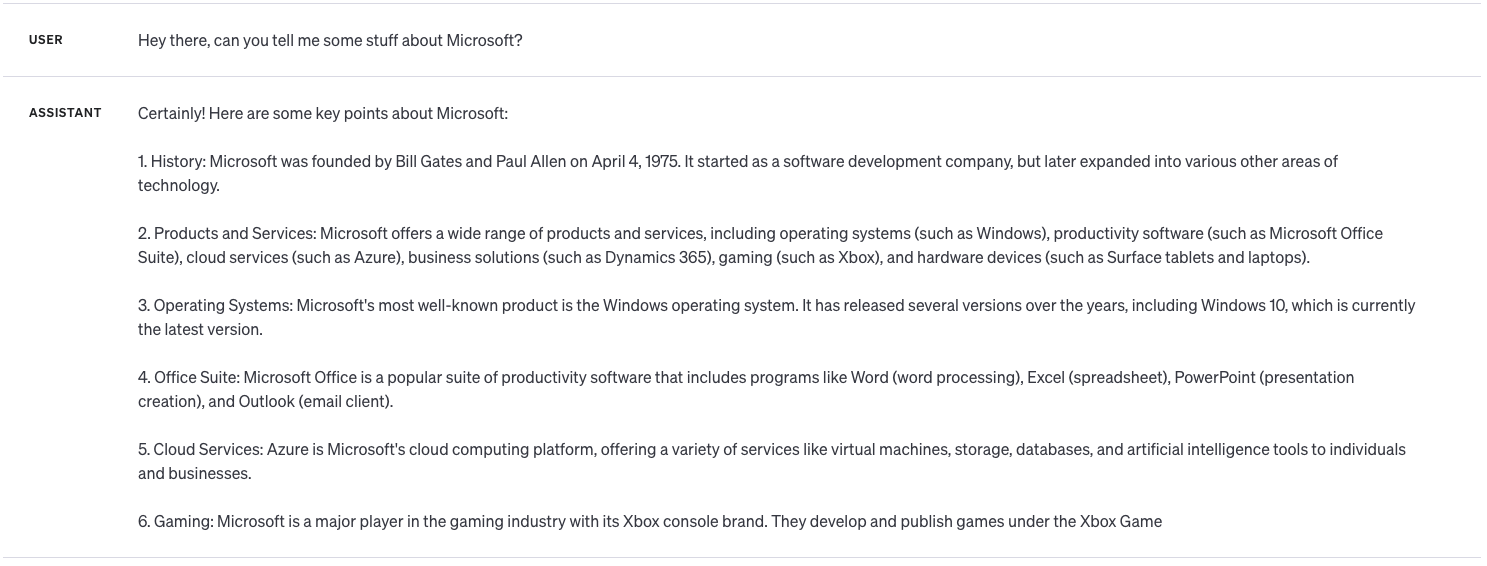
Much better right! If we wanted that even more precise, but potentially with less info and more repetitive completions, we’d head even closer to 0 / a lower value.
Maximum length aka… tokens
Let’s finish up by talking about one more parameter we can play with when making requests to the model we’ve chosen. We have the maximum length parameter to determine the amount of tokens to generate shared between the prompt and completion. Typically there’s about 4 English characters to a token so you can use this to adjust the size of the completion you get, again potentially shaping that response to be more concise and precise to your query or prompt. On the flip side, you’d possibly consider increasing this value to ensure your AI product returns enough information to the people prompting it… 💯
Homework
So friends… you want something to do to get ahead of the game here? Here’s the things to do…
- Check out OpenAI’s API playground here… Playground – OpenAI API, play with the various parameters to get a feel for how to ground the AI ready to build your AI products.
- Check out the Azure AI Studio, and if you don’t yet have access and are a Microsoft FTE, MVP, Systems Integrator, or enterprise customer, request access now – https://aka.ms/oai/access
- Start building your AI products. Get started here – https://lewisdoes.dev/blog/build-your-own-copilot-with-javascript-and-openai-part-1
Kudos
Kudos and thank you’s go to Dona Sarkar for her teaching on this topic specifically at South Coast Summit last weekend in her Dev Kitchen workshop with Chris H and Will D, as well as to Scott Hanselman, and friends in the Build AI Day keynote 💖
Did you like this content? 💖
Did you like this content? Check out some of the other posts on my blog, and if you like those too, be sure to subscribe to get my posts directly in your inbox for free!
Subscribe